
模型发展
CNN/RNN是老算法架构,逐渐转向Transformer;TensorFlow是老框架层,逐渐转向PyTorch
| 层次 | 2018 年 | 2025 年(现在) |
|---|---|---|
| 框架层 | TensorFlow(主导) | PyTorch(主导),JAX(科研) |
| 模型结构 | CNN、RNN | Transformer、Diffusion |
| 工具生态 | TensorBoard、TF Serving | HuggingFace、Lightning、vLLM、OpenAI Triton |
| 部署方案 | TF Lite、TF Serving | TorchScript、ONNX、TensorRT、vLLM、Mistral Engine |
| 趋势方向 | 静态计算图 + 手工优化 | 动态计算 + 自动图融合 + 大模型编译器(e.g. TensorRT-LLM, Mojo, TorchDynamo) |
Transformer和基础知识
优势:长Context能力强,“Attention is all you need”。核心思想在于Self-Attention。
Q,K,V: Query, Key, Value,用于计算词之间的关联度
softmax: 一个重要算子,可以把分数转换为概率;例如用在NTP预测分数输出分数y,需要softmax为概率再去和one-hot答案向量去做交叉熵
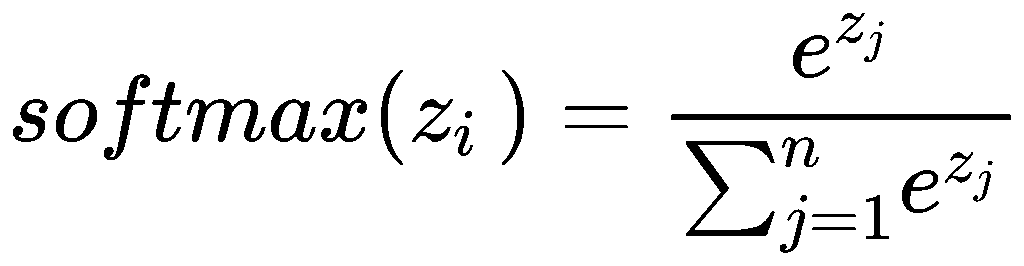
交叉熵计算Loss:
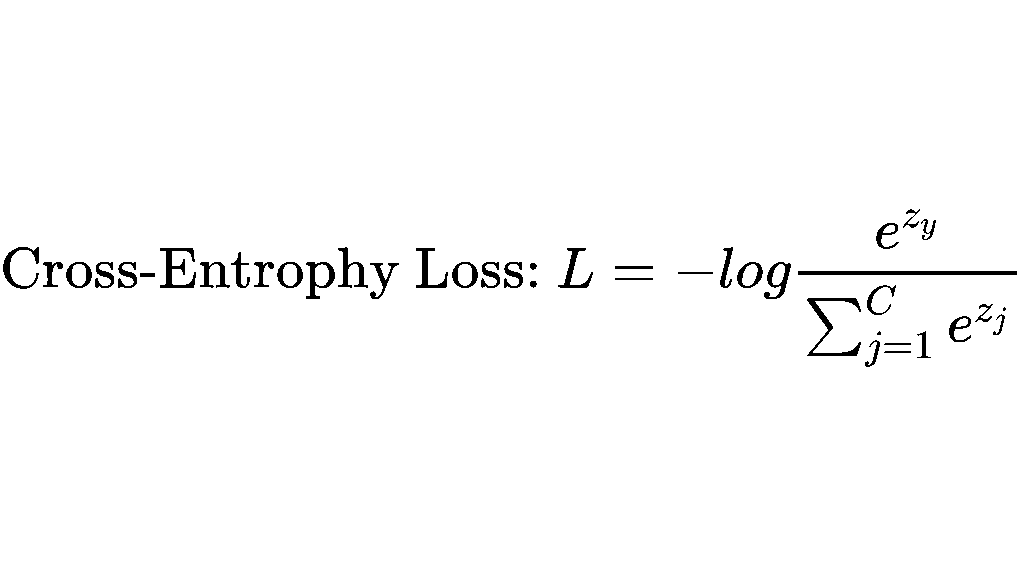
训练流程-训练层
训练目标
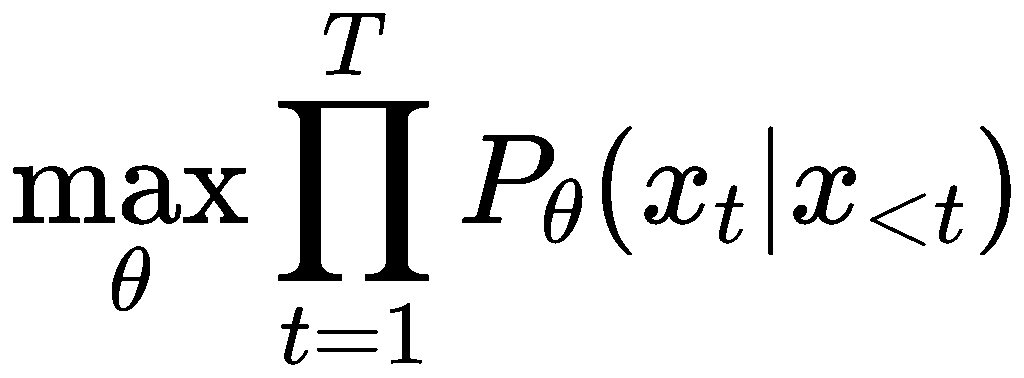
其中θ是所有的可训练参数,T是token序列的长度,所以目标是让正确的词预测出现概率最大,这个式子取对数后加上负号也就是交叉熵损失的式子了。
训练步骤
分为Input Tokens,Embedding + Positional Encoding,Transformer Blocks,Output Logits,Softmax,Cross Entropy Loss,Backpropagation和Optimizer。
会把(x,y)打包成batch,作为一个训练批次,每个(x,y)会独立计算loss,只有在back propagation里会取均值并且让可训练参数做梯度下降。
batch的意义在于每个样本的梯度可能很噪(尤其输入差异大时),梯度波动小 → 更新方向更稳定 → 训练更平滑。反向传播参数更新有一些优化器,比如说SGD / Adam / AdamW等等。
Input Tokens
- Raw Input 先经过 Tokenizer(分词器),映射成整数Id列表,形成 Input Tokens,长度为n
Embedding + Positional Encoding
- 找到每个 token 的 embedding,形成 n 行 d 列的矩阵 Embedding(tokeni)。其中d是embedding的维度。每行对应一个 token 的 embedding 向量。
- Embedding(E)是一个一个token的向量表达形式,具有语义性。通过E可以算出QKV,以此得到token之间的关联度。同时E之间也具有运算逻辑,对于一个优秀的模型,比如E["Queen"]约等于E["King"]+E["Woman"]-E["Man"]。
- Transformer 是基于 自注意力(Self-Attention) 的结构。
在自注意力中,每个 token 都能和别的 token 直接交互,但它 没有循环结构(不像 RNN),也 没有卷积核(不像 CNN)。
所以如果不给模型顺序信息,它只会看到一堆词,根本不知道谁在前谁在后。
所以需要加上位置编码(Positional Encoding):
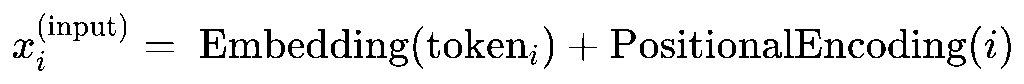
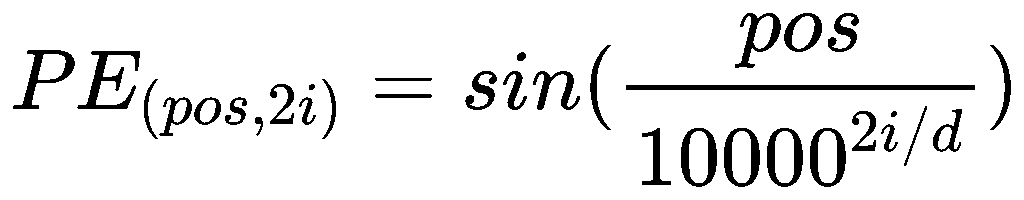
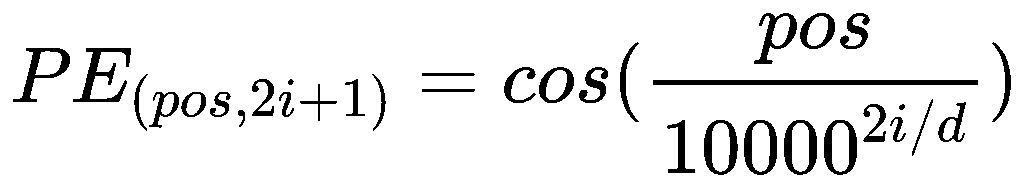
- pos 是词在句子中的位置(从 0 开始);
- i 是维度索引;
- d 是 embedding 的维度。
- 偶数维用 sin;奇数维用 cos;高维部分变化更慢,低维部分变化更快;模型能据此推断出词之间的相对位置信息。
所以最终输出是 n 行 d 列的矩阵X。
Transformer Blocks
分为四个步骤,Multi-Head Self-Attention,Add & Norm,Feed Forward Network (FFN),最后Add & Norm。
Multi-Head Self-Attention
Head是注意力模式,不同的head学习不同的注意力模式。例如:一个 head 学语法关系(主谓);一个head 学长程依赖(句首与句尾);一个 head 学词义关联(同义词、上下文)
对于每个Head,都有三个可学习矩阵WQ,WK,WV,分别可以提取出Query, Key, Value,根据Q=X·WQ,K=X·WK,V=X·WV,算出Q、K、V。
W_Q:告诉模型“哪些信号组成 Query,用来提问/找信息”
W_K:告诉模型“哪些信号组成 Key,用来被匹配”
W_V:告诉模型“哪些信号组成 Value,用来输出/传递信息”
Query(Q) = “我现在想要关注什么?”
Key(K) = “候选 token 的索引特征”
Value(V) = “候选 token 的实际内容”
然后:
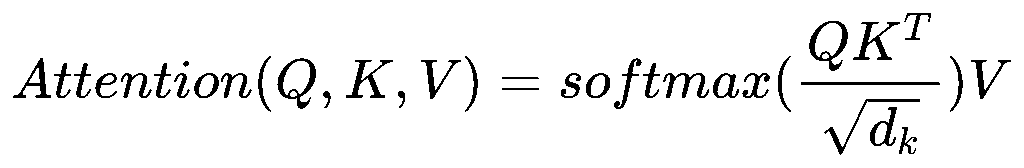
QK^T:衡量 token i 的 query 与 token j 的 key 的相似度,其中相似度是采用乘积的形式
d_k:单个 head 的 Query/Key/Value 维度:
- 每个 Multi-Head Attention 会把 embedding 拆成
h个 head - 每个 head 的维度:d_k=d_model / h
- d_model就是embedding的维度
除以 √d_k:
- 原因:高维向量点积会变大 → softmax 梯度很小 → 梯度消失
- 缩放可以 保持 softmax 输入的尺度稳定,训练更平稳
- 改变d_k的大小就可以让关注度改变,可以集中于几个token,也可以分散关注更多的token
softmax的结果:相似度进行归一化,是一个n*n的矩阵
softmax*V:
- softmax(QK^T/√d_k) = “我(Query)现在想看谁的信息多一点”
- 乘 V = “把关注到的 token 信息按权重加起来,形成新的 token 表示”
- Attention 输出每个 token 的新向量 = 综合它想关注的所有 token 的信息
- 是一个信息的表示,表示第 i 个 token 的上下文向量,是 n 行 d 列的。
Add & Norm
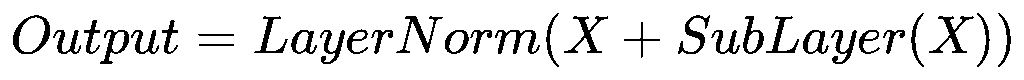
第一次:X指PE的输出(即Attention的输入),SubLayer(x)指Attention的输出
第二次:X指FFN的输入,SubLayer(x)指FFN的输出
LayerNorm公式如下:
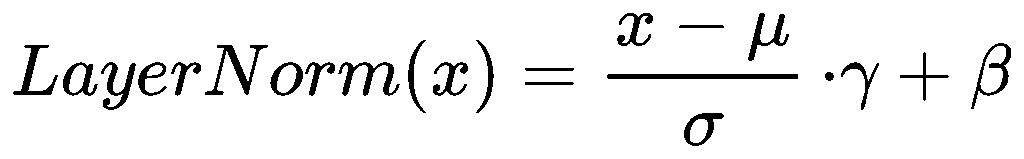
其中μ是均值,σ是标准差;γ, β表示幅度和偏移,是可训练参数;LayerNorm是对每行做的,所以γ, β都是行向量,长度为d。
LayerNorm在通过γ, β前,均值为0,方差为1;γ决定每个特征贡献多大,β决定特征偏移(基准值)
FFN
FFN 是 两层全连接 + 非线性激活,经过顺序是全连接W1、非线性激活(ReLU/GeLU等)、全连接W2
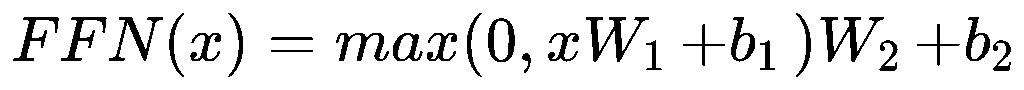
ReLU(Rectified Linear Unit):ReLU(x)=max(0,x)
GeLU(Gaussian Error Linear Unit):GeLU(x)=x·Φ(x),其中Φ(x)是正态分布中的CDF
实际上 Transformer 中通常用近似公式:
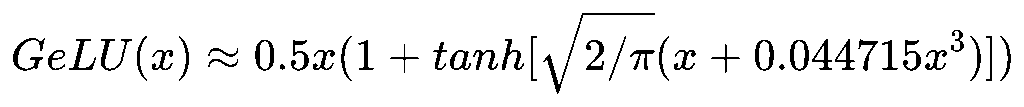
- 平滑非线性 → 与 ReLU 的硬切断不同
- 概率性质 → 可以理解为“以概率 x 通过”
- 梯度连续 → 更容易训练深层网络
Output Logits + Softmax
在Transformer Blocks中输出了一个n×d的token特征矩阵,对于NTP(Next Token Prediction)来说,需要一层线形+softmax转换成词表概率:
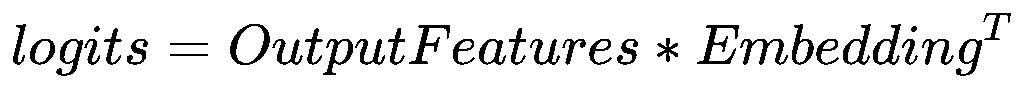
得到的的是一个n×sz(词表)的矩阵,代表每个token的预测下一个词分数,对每行做一个softmax即为NTP概率。
Cross Entropy Loss
即交叉熵,正确token预测分数越高,即交叉熵越低,预测的越好。因为NTP的目标是一个one-hot向量(即只有一个位置是1,其余是0,表示该token是标准答案),所以有:
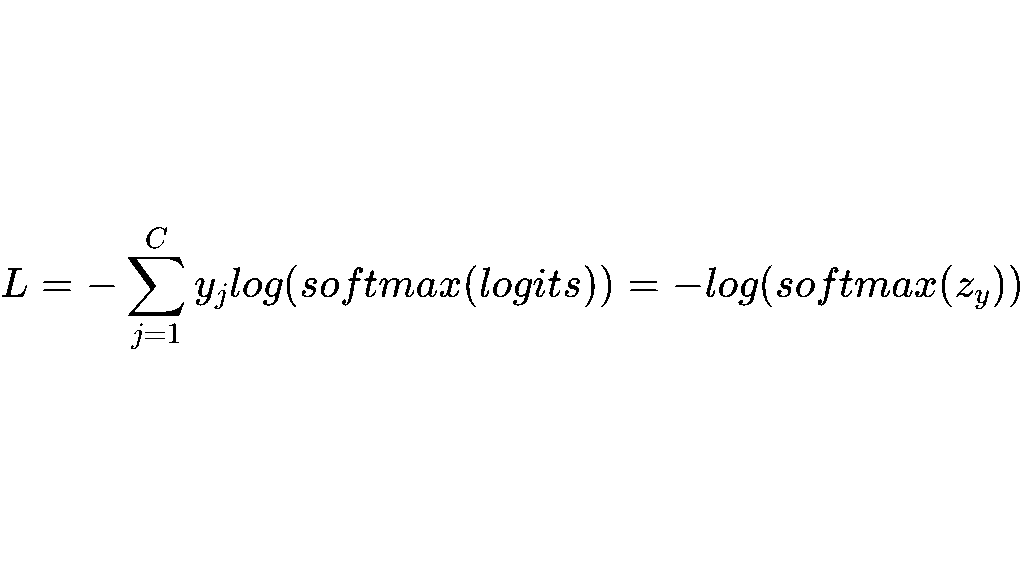
Backpropagation
上文中提到了多个可训练参数,称它们为xi,包括Embedding矩阵、Attention权重WQ、WK、WV、FFN权重W1/W2/b1/b2、LayerNorm γ/β等。我们需要计算每个可训练参数的梯度,即这些参数如何调整才能使得交叉熵降低,即计算:
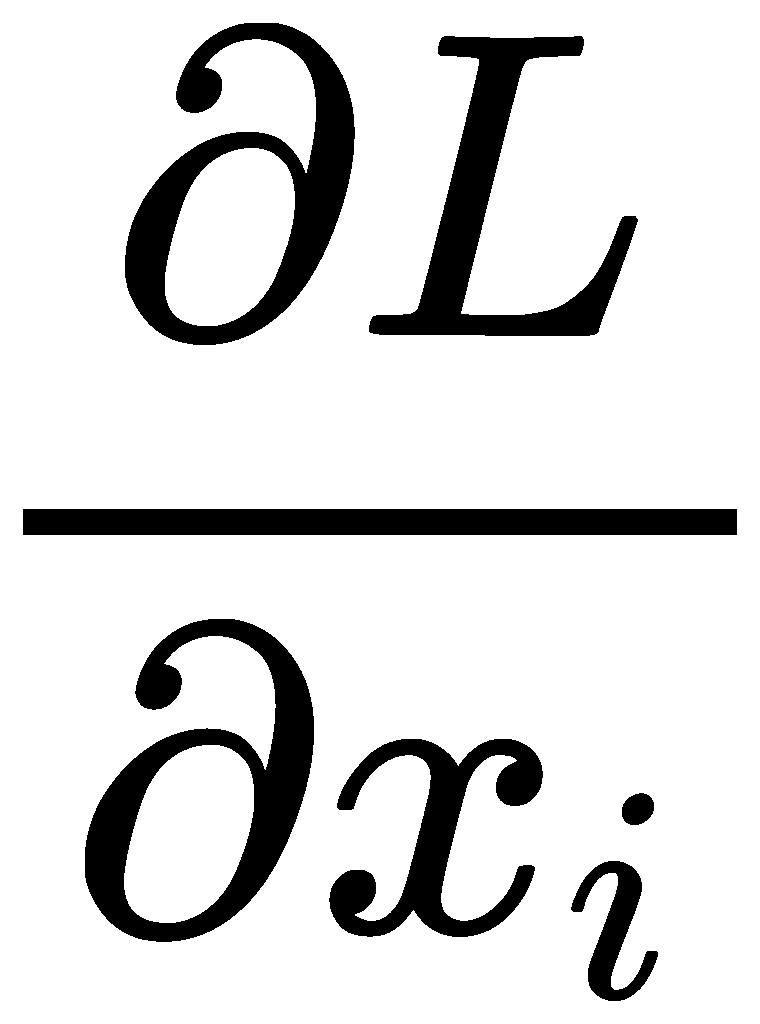
Optimizer
利用梯度更新参数,使Loss下降;Optimizer有许多策略,不同optimizer有不同算法。
| Optimizer | 更新规则 | 特点 |
|---|---|---|
| SGD | 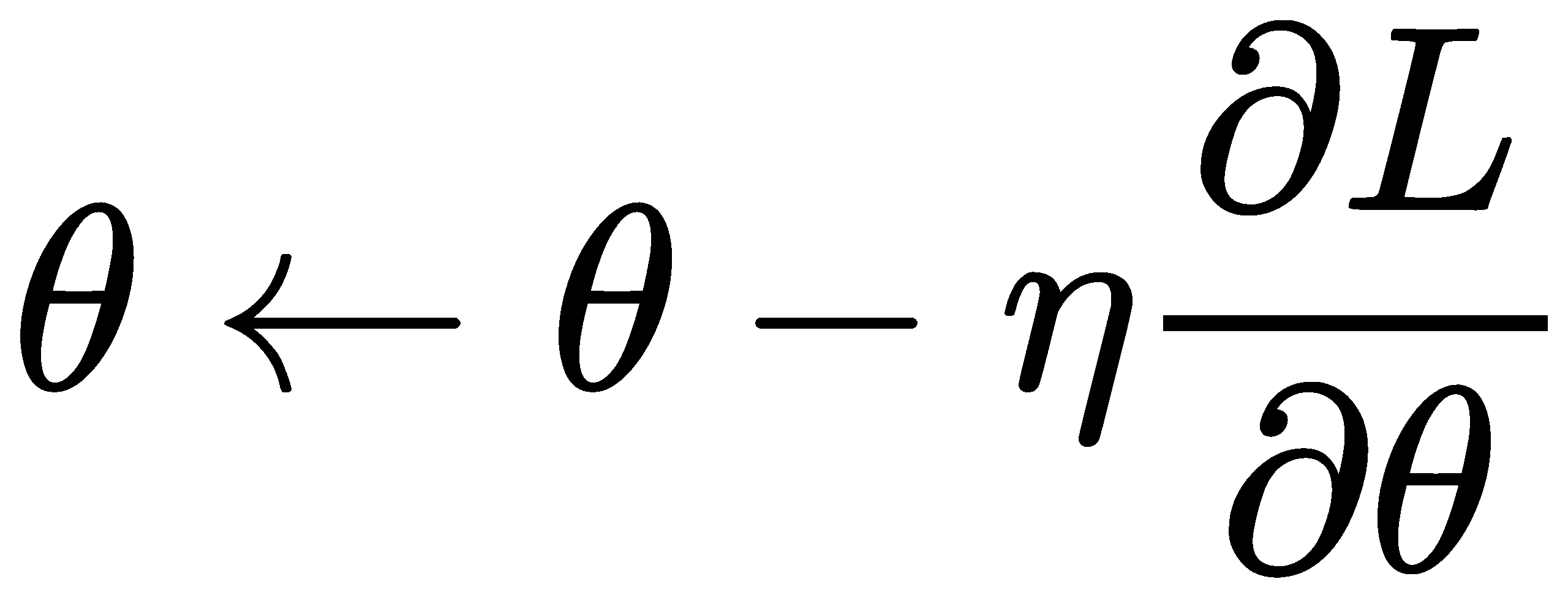 |
最简单,学习率固定 |
| SGD + Momentum | 考虑动量,加速收敛 | 避免震荡 |
| Adam / AdamW | 自适应学习率 + 动量 | 适合大规模 Transformer |
| RMSProp | 自适应学习率 | 平滑梯度变化 |
简单介绍Adam:记训练的步数为t,梯度为gt,mt为一阶矩,vt为二阶矩:

修正偏差后:
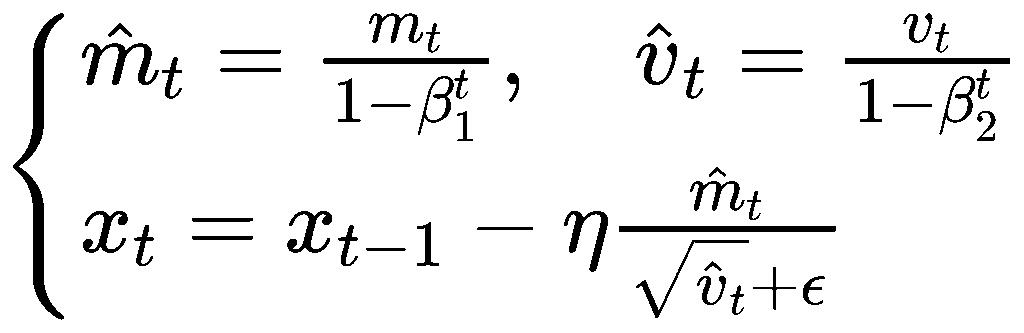
系统层
| 模块 | 功能 |
|---|---|
| 数据加载 (Data Pipeline) | 从磁盘高效读取 token 化后的训练数据 |
| Batching & Padding | 让每个 batch 的输入形状统一,支持并行计算 |
| GPU / TPU 加速 | 用 CUDA、cuDNN、PyTorch 的 GPU 计算 |
| 多 GPU 分布式训练 (DDP / ZeRO / FSDP) | 模型太大时跨设备并行训练 |
| 显存优化 | 梯度检查点、混合精度 (FP16/BF16) |
| 训练日志与监控 | loss 曲线、学习率、显存监控 |
| Checkpoint / Resume | 保存和恢复模型参数 |
| 推理优化 (KV Cache, TensorRT, ONNX) | 让生成阶段更快、更省资源 |
Comments NOTHING